


Çelësi për zhvillimin e modeleve fleksibël të të mësuarit të makinerive që janë të afta të arsyetojnë siç bëjnë njerëzit, mund të mos jetë duke u ushqyer atyre një mori të dhënash trajnimi. Në vend të kësaj, sugjeron një studim i ri, mund të varet nga mënyra se si ata janë trajnuar. Këto gjetje mund të jenë një hap i madh drejt modeleve më të mira, më pak të prirura ndaj gabimeve të inteligjencës artificiale dhe mund të ndihmojnë në ndriçimin e sekreteve se si sistemet e AI-dhe njerëzit- mësojnë.
Njerëzit janë ripërzierësit kryesorë. Kur njerëzit kuptojnë marrëdhëniet midis një grupi përbërësish, si përbërësit e ushqimit, ne mund t’i kombinojmë ato në të gjitha llojet e recetave të shijshme. Me gjuhën, ne mund të deshifrojmë fjali që nuk i kemi hasur kurrë më parë dhe të krijojmë përgjigje komplekse, origjinale, sepse kuptojmë kuptimet themelore të fjalëve dhe rregullat e gramatikës. Në terma teknikë, këta dy shembuj janë dëshmi e “kompozicionit” ose “përgjithësimit sistematik” – shpesh i parë si një parim kyç i njohjes njerëzore. “Unë mendoj se ky është përkufizimi më i rëndësishëm i inteligjencës,” thotë Paul Smolensky, një shkencëtar njohës në Universitetin Johns Hopkins. “Ju mund të kaloni nga njohja e pjesëve në trajtimin me të tërën.”
Përbërja e vërtetë mund të jetë thelbësore për mendjen e njeriut, por zhvilluesit e mësimit të makinerive kanë luftuar për dekada për të provuar se sistemet e AI mund ta arrijnë atë. Një argument 35-vjeçar i bërë nga filozofët e ndjerë dhe shkencëtarët njohës Jerry Fodor dhe Zenon Pylyshyn parashtron se parimi mund të jetë i paarritshëm për rrjetet nervore standarde. Modelet e sotme gjeneruese të AI mund të imitojnë përbërjen, duke prodhuar përgjigje njerëzore ndaj kërkesave me shkrim. Megjithatë, edhe modelet më të avancuara, përfshirë GPT-3 dhe GPT-4 të OpenAI, ende nuk arrijnë disa standarde të kësaj aftësie. Për shembull, nëse i bëni një pyetje ChatGPT, ai fillimisht mund të japë përgjigjen e saktë. Megjithatë, nëse vazhdoni t’i dërgoni pyetje pasuese, ajo mund të dështojë të qëndrojë në temë ose të fillojë të kundërshtojë vetveten. Kjo sugjeron që megjithëse modelet mund të rikthejnë informacionin nga të dhënat e tyre të trajnimit, ata nuk e kuptojnë me të vërtetë kuptimin dhe qëllimin pas fjalive që prodhojnë.
Por një protokoll i ri trajnimi që përqendrohet në formimin e mënyrës sesi mësojnë rrjetet nervore mund të rrisë aftësinë e një modeli të AI për të interpretuar informacionin ashtu siç bëjnë njerëzit, sipas një studimi të botuar të mërkurën në Nature. Gjetjet sugjerojnë se një qasje e caktuar ndaj edukimit të AI mund të krijojë modele kompozicionale të mësimit të makinerive që mund të përgjithësojnë po aq mirë sa njerëzit – të paktën në disa raste.
“Ky hulumtim thyen terren të rëndësishëm,” thotë Smolensky, i cili nuk ishte i përfshirë në studim. “Ai realizon diçka që ne kemi dashur të arrijmë dhe nuk kemi pasur sukses më parë.”
Për të trajnuar një sistem që duket i aftë për të rikombinuar komponentë dhe për të kuptuar kuptimin e shprehjeve të reja, komplekse, studiuesit nuk duhej të ndërtonin një AI nga e para. “Ne nuk kishim nevojë të ndryshonim rrënjësisht arkitekturën,” thotë Brenden Lake, autori kryesor i studimit dhe një shkencëtar njohës kompjuterik në Universitetin e Nju Jorkut. “Ne thjesht duhej t’i jepnim praktikë.” Hulumtuesit filluan me një model standard transformatori – një model që ishte i njëjti lloj skela AI që mbështet ChatGPT dhe Bard të Google, por i mungonte ndonjë trajnim paraprak me tekst. Ata e drejtuan atë rrjet bazë nervor përmes një grupi detyrash të krijuara posaçërisht që synonin t’i mësonin programit se si të interpretonte një gjuhë të krijuar.
Gjuha përbëhej nga fjalë të pakuptimta (të tilla si “dax”, “lug”, “kiki”, “fep” dhe “blicet”) që “përktheheshin” në grupe pikash shumëngjyrëshe. Disa nga këto fjalë të shpikura ishin terma simbolikë që përfaqësonin drejtpërdrejt pika të një ngjyre të caktuar, ndërsa të tjera nënkuptonin funksione që ndryshonin rendin ose numrin e daljeve të pikave. Për shembull, dax përfaqësonte një pikë të kuqe të thjeshtë, por fep ishte një funksion që, kur çiftohej me dax ose ndonjë fjalë tjetër simbolike, shumëzoi daljen e saj përkatëse të pikës me tre. Pra, “dax fep” do të përkthehej në tre pika të kuqe. Megjithatë, trajnimi i AI nuk përfshiu asnjë nga ato informacione: studiuesit thjesht i dhanë modeles një grusht shembujsh fjalish të pakuptimta të çiftëzuara me grupet përkatëse të pikave.
Nga atje, autorët e studimit e nxitën modelin të prodhonte serinë e vet të pikave në përgjigje të frazave të reja, dhe ata e vlerësuan AI nëse kishte ndjekur saktë rregullat e nënkuptuara të gjuhës. Së shpejti rrjeti nervor ishte në gjendje të përgjigjej në mënyrë koherente, duke ndjekur logjikën e gjuhës së pakuptimtë, edhe kur u njoh me konfigurime të reja fjalësh. Kjo sugjeron se mund të “kuptojë” rregullat e sajuara të gjuhës dhe t’i zbatojë ato në frazat për të cilat nuk ishte trajnuar.
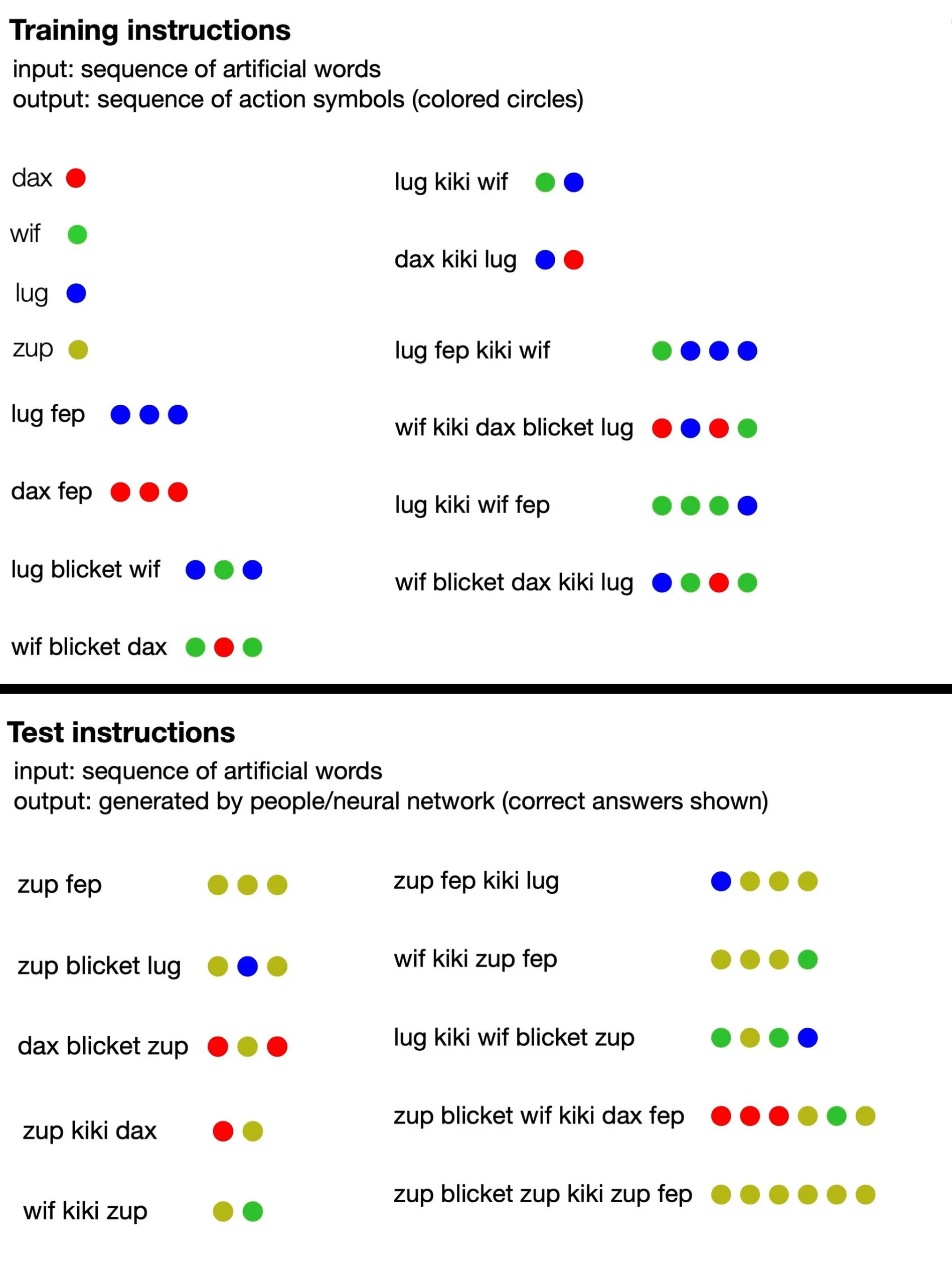 Për më tepër, studiuesit testuan të kuptuarit e gjuhës së sajuar nga modeli i tyre i trajnuar i AI kundër 25 pjesëmarrësve njerëzorë. Ata zbuluan se, në rastin më të mirë, rrjeti i tyre nervor i optimizuar u përgjigj 100 për qind me saktësi, ndërsa përgjigjet njerëzore ishin të sakta rreth 81 për qind të kohës. (Kur ekipi ushqeu GPT-4 kërkesat e trajnimit për gjuhën dhe më pas i bëri pyetjet e testit, modeli i madh i gjuhës ishte vetëm 58 përqind i saktë.) Duke pasur parasysh trajnimin shtesë, modeli standard i transformatorit të studiuesve filloi të imitonte aq mirë arsyetimin njerëzor se ai bëri të njëjtat gabime: Për shembull, pjesëmarrësit njerëz shpesh gabonin duke supozuar se kishte një marrëdhënie një-për-një midis fjalëve dhe pikave specifike, edhe pse shumë nga frazat nuk ndiqnin atë model. Kur modelit iu dhanë shembuj të kësaj sjelljeje, ai shpejt filloi ta përsëriste atë dhe bëri gabimin me të njëjtën frekuencë si njerëzit.
Për më tepër, studiuesit testuan të kuptuarit e gjuhës së sajuar nga modeli i tyre i trajnuar i AI kundër 25 pjesëmarrësve njerëzorë. Ata zbuluan se, në rastin më të mirë, rrjeti i tyre nervor i optimizuar u përgjigj 100 për qind me saktësi, ndërsa përgjigjet njerëzore ishin të sakta rreth 81 për qind të kohës. (Kur ekipi ushqeu GPT-4 kërkesat e trajnimit për gjuhën dhe më pas i bëri pyetjet e testit, modeli i madh i gjuhës ishte vetëm 58 përqind i saktë.) Duke pasur parasysh trajnimin shtesë, modeli standard i transformatorit të studiuesve filloi të imitonte aq mirë arsyetimin njerëzor se ai bëri të njëjtat gabime: Për shembull, pjesëmarrësit njerëz shpesh gabonin duke supozuar se kishte një marrëdhënie një-për-një midis fjalëve dhe pikave specifike, edhe pse shumë nga frazat nuk ndiqnin atë model. Kur modelit iu dhanë shembuj të kësaj sjelljeje, ai shpejt filloi ta përsëriste atë dhe bëri gabimin me të njëjtën frekuencë si njerëzit.
Performanca e modelit është veçanërisht e jashtëzakonshme, duke pasur parasysh madhësinë e tij të vogël. “Ky nuk është një model i madh gjuhësor i trajnuar në të gjithë internetin; ky është një transformator relativisht i vogël i trajnuar për këto detyra”, thotë Armando Solar-Lezama, një shkencëtar kompjuteri në Institutin e Teknologjisë në Massachusetts, i cili nuk ishte i përfshirë në studimin e ri. “Ishte interesante të shihje se megjithatë është në gjendje të shfaqë këto lloj përgjithësimesh.” Gjetja nënkupton se në vend që të futen gjithnjë e më shumë të dhëna trajnimi në modelet e mësimit të makinerive, një strategji plotësuese mund të jetë ofrimi i algoritmeve të AI ekuivalent i një klase të fokusuar të gjuhësisë ose algjebrës.
Solar-Lezama thotë se kjo metodë e trajnimit teorikisht mund të sigurojë një rrugë alternative drejt AI më të mirë. “Pasi të keni ushqyer një model të gjithë internetin, nuk ka internet të dytë për ta ushqyer atë për t’u përmirësuar më tej. Kështu që unë mendoj se strategjitë që i detyrojnë modelet të arsyetojnë më mirë, madje edhe në detyra sintetike, mund të kenë një ndikim në të ardhmen,” thotë ai – me paralajmërimin se mund të ketë sfida për të shkallëzuar protokollin e ri të trajnimit. Njëkohësisht, Solar-Lezama beson se studime të tilla të modeleve më të vogla na ndihmojnë të kuptojmë më mirë “kutinë e zezë” të rrjeteve nervore dhe mund të hedhin dritë mbi të ashtuquajturat aftësi emergjente të sistemeve më të mëdha të AI.
Smolensky shton se ky studim, së bashku me punë të ngjashme në të ardhmen, mund të rrisë gjithashtu të kuptuarit e mendjes sonë nga njerëzit. Kjo mund të na ndihmojë të krijojmë sisteme që minimizojnë prirjet e prirjes ndaj gabimeve të specieve tona. scientificamerican
Që nga viti 2015 nxisim shpirtin sipërmarrës, inovacionin dhe rritjen personale duke ndikuar në zhvillimin e një mjedisi motivues dhe pozitiv tek lexuesit tanë. Mbështetja juaj na ndihmon ta vazhdojmë këtë mision.
Na Suporto
