

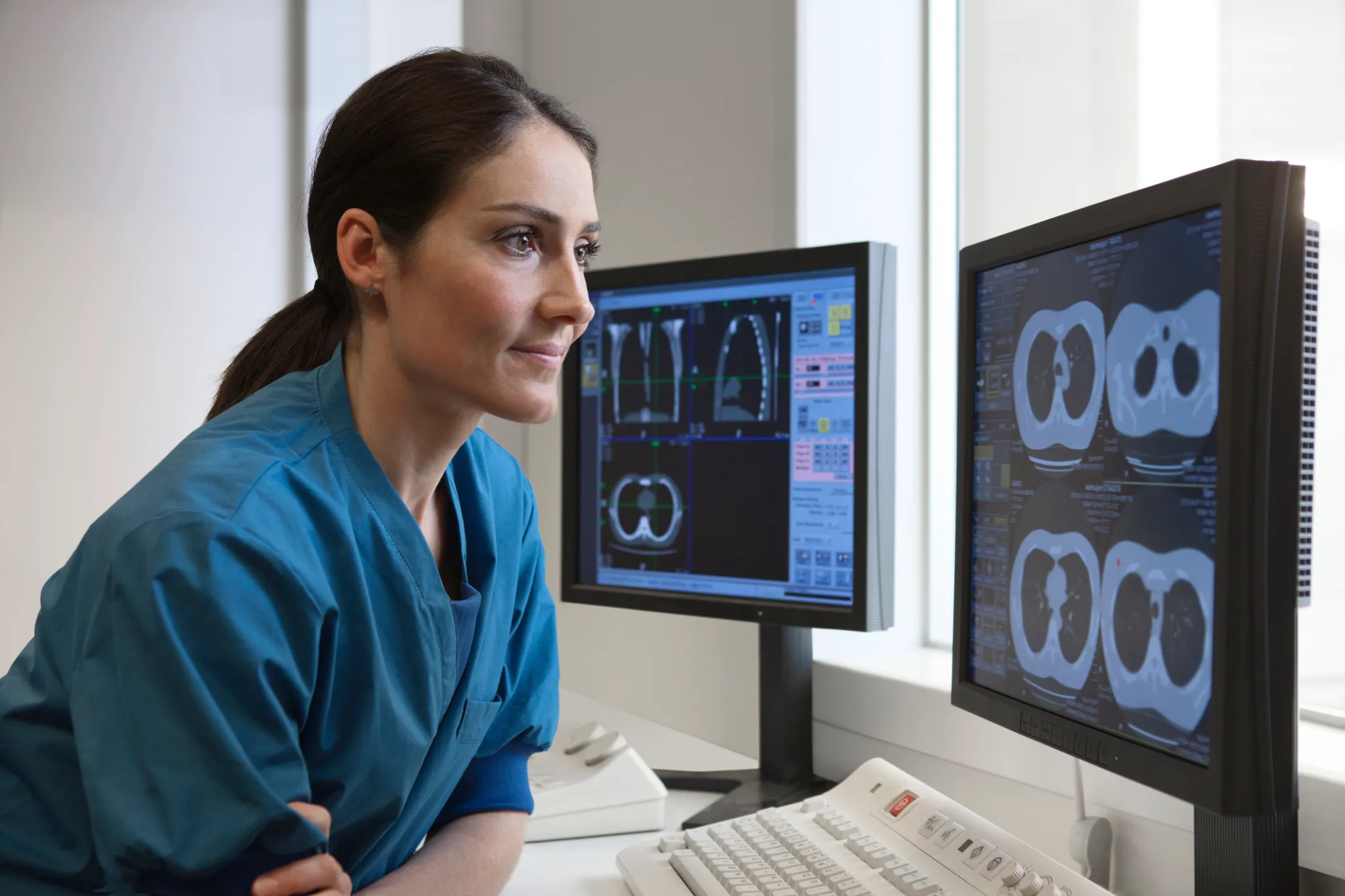
Një studim i ri ka analizuar performancën e modeleve të inteligjencës artificiale në kontekste të ndryshme mjekësore, përfshirë raste reale të urgjencës, ku të paktën një model rezultoi më i saktë se mjekët njerëzorë në vendosjen e diagnozës.
Studimi u publikua këtë javë në revistën shkencore Science dhe është realizuar nga një ekip kërkuesish të udhëhequr nga mjekë dhe shkencëtarë kompjuterikë në Harvard Medical School dhe Beth Israel Deaconess Medical Center. Qëllimi ishte të krahasohej performanca e modeleve të OpenAI me atë të mjekëve në situata reale klinike.
Në një nga eksperimentet kryesore, studiuesit analizuan 76 pacientë që u paraqitën në urgjencën e Beth Israel, duke krahasuar diagnozat e dhëna nga dy mjekë të mjekësisë interne me ato të gjeneruara nga modelet e OpenAI, përfshirë o1 dhe 4o. Vlerësimi u bë nga dy mjekë të tjerë, të cilët nuk e dinin nëse diagnozat vinin nga njerëzit apo nga inteligjenca artificiale.
Sipas studimit, në çdo fazë të procesit diagnostik, modeli o1 performoi njësoj ose më mirë se mjekët dhe modeli 4o. Diferencat ishin më të theksuara në fazën e parë të vlerësimit në urgjencë, aty ku informacioni për pacientin është i kufizuar dhe vendimmarrja duhet të jetë e shpejtë.
Në njoftimin zyrtar të Harvard Medical School theksohet se modelet nuk iu nënshtruan asnjë përpunimi paraprak të të dhënave, por u furnizuan me të njëjtin informacion që ishte i disponueshëm në kartelat elektronike të pacientëve në momentin e diagnozës. Në këto kushte, modeli o1 arriti të japë diagnozë të saktë ose shumë të afërt në 67% të rasteve gjatë triazhit, krahasuar me 55% dhe 50% për dy mjekët respektivë.
Lexo edhe: Çfarë tregon automobili elektrik i Renault-it për industrinë
“Ne e testuam modelin e inteligjencës artificiale në pothuajse çdo benchmark të mundshëm dhe ai tejkaloi si modelet e mëparshme, ashtu edhe performancën bazë të mjekëve,” u shpreh Arjun Manrai, drejtues i një laboratori të AI në Harvard dhe një nga autorët kryesorë të studimit.
Megjithatë, studiuesit janë të kujdesshëm në interpretimin e rezultateve. Ata nuk pretendojnë se AI është gati të marrë vendime jetike në ambientet e urgjencës, por theksojnë nevojën urgjente për studime të mëtejshme në kushte reale për të vlerësuar përdorimin e këtyre teknologjive në kujdesin ndaj pacientëve.
Një tjetër kufizim i rëndësishëm i studimit është se analiza është bërë vetëm mbi të dhëna tekstuale. Sipas autorëve, modelet aktuale kanë ende kufizime në interpretimin e inputeve jo-tekstuale, si imazhet apo sinjalet klinike.
Adam Rodman, një mjek në Beth Israel dhe bashkautor i studimit, theksoi se aktualisht mungon një kuadër i qartë përgjegjësie për diagnozat e dhëna nga inteligjenca artificiale. Ai shtoi se pacientët ende kërkojnë udhëzim njerëzor, veçanërisht kur bëhet fjalë për vendime të vështira dhe situata jetë a vdekje.
Ndërkohë, jo të gjithë ekspertët janë entuziastë për mënyrën si po interpretohen këto rezultate. Kristen Panthagani, mjeke urgjence, e cilësoi studimin interesant, por paralajmëroi për rrezikun e titujve të ekzagjeruar. Ajo vuri në dukje se krahasimi është bërë me mjekë të mjekësisë interne dhe jo me specialistë të urgjencës.
Sipas saj, në praktikën e urgjencës, qëllimi kryesor nuk është domosdoshmërisht identifikimi i menjëhershëm i diagnozës përfundimtare, por vlerësimi nëse pacienti ka një gjendje që mund të jetë fatale dhe kërkon ndërhyrje të menjëhershme.
Që nga viti 2015 nxisim shpirtin sipërmarrës, inovacionin dhe rritjen personale duke ndikuar në zhvillimin e një mjedisi motivues dhe pozitiv tek lexuesit tanë. Mbështetja juaj na ndihmon ta vazhdojmë këtë mision.
Na Suporto
